
KNN 모델을 지도학습의 분류로 학습시켜 Iris 붓꽃 품종 분류 실습하다.
전 글에서 다뤘던 지도학습의 7단계 과정으로 Iris 붓꽃 품종 분류를 하고 일반화, 과대적합, 과소적합 개념들과 문제데이터, 정답데이터를 분리하고 각각의 데이터를 훈련데이터, 평가데이터를 비율에 맞춰서 나눠야 하는데 기존에 사용했던 인덱싱의 문제점을 설명하고 새롭게 train_test_split( ) 함수를 사용해서 나누는 방법도 설명하겠다.
1. 문제 정의
머신러닝 모델 학습의 목표를 구상하는 서류작성 단계?로 생각하기
- 목표 : 붓꽃의 품종을 구분하는 머신러닝 모델 만들기
- 사용할 학습 방법 : 지도학습 - 분류
2. 데이터 수집
sklearn에서 기본적으로 제공하는 Iris 데이터셋을 사용하기 때문에 딱히 csv파일을 읽는다거나 그런 작업은 없다.
from sklearn.datasets import load_iris
iris_data = load_iris()sklearn 데이터셋으로부터 iris 데이터를 load 한다. iris_data라는 변수에 담아서 어떻게 들어있는지 확인해 본다.


확인했을 때 딕셔너리 형태로 되어있다. 하지만 단순 딕셔너리 형태가 아닌 여러 가지 타입이 딕셔너리 안에 요소로 존재한다.
배열도 있고 문자열도있고 여러 가지다. 이것을 bunch 객체라고 한다. bunch는 '다발'이라는 뜻인데 딕셔너리 안에 여러 가지 타입의 요소가 있으면 bunch객체라고 한다. 이 딕셔너리의 key값만 확인하여 대충보단 더 자세히 어떤 데이터가 들어있는지 확인해야 할 것 같다.

딕셔너리 이름에 keys( )함수를 사용하면 해당 딕셔너리 안의 어떤 key들이 들어있는지 알려준다.
붓꽃의 품종은 꽃받침의 길이, 너비, 꽃잎의 길이, 너비를 기준으로 3가지 품종으로 구분한다. 이 4가지 데이터는 'data' key의 value에 있다.

이 데이터들은 X에 해당하는 데이터라는 걸 알아야 한다.

그렇다면 y는 무엇인지 확인해보겠다. y는 품종의 이름인 target_names인 것 같지만 해당 데이터는 품종을 숫자로 구분하고 있다. key가 target인 데이터를 확인하면 0부터 2까지 오름차순 정렬로 되어있는 것을 볼 수 있다.
0이면 setosa, 1이면 versicolor, 2면 virginica.
3. 데이터 전처리
학습용으로 제작된 데이터이기 때문에 데이터 전처리가 필요하지 않다.
4. 탐색적 데이터 분석 (EDA)
학습용으로 제작된 데이터이기 때문에 이 과정이 필요하지 않다. 문제와 정답으로 나눈 후 산점도를 행렬로 표시할 것이다.
5. 모델 선택 및 하이퍼 파라미터 튜닝
5 - 1. KNN 모델 불러오기
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier()
5 - 2. 데이터 분리하기
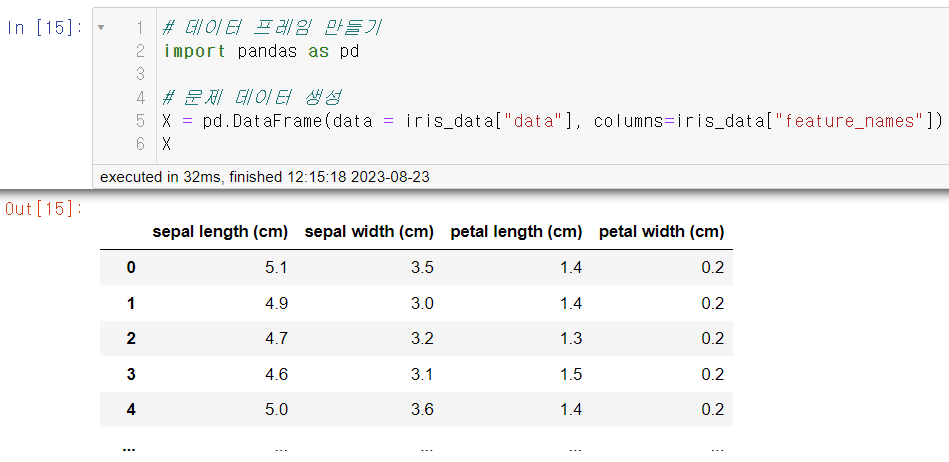
X 데이터를 사용하기위해선 데이터 프레임 형태여야 한다. 현재 X데이터는 2차원배열이기 때문에 pandas르 불러와서 데이터 프레임형태로 변경해 주면 된다. 컬럼은 feature_names으로 각각 해주면 된다. 이렇게 X 데이터를 만들었다.

y는 데이터프레임 형태가 아닌 시리즈 형태여야 하기 때문에 pandas로 데이터 프레임 형태로 바꿔줄 필요가 없다.
5 - 3. train_test_split( ) 함수

이제 X, y데이터를 훈련용 데이터와 평가용 데이터로 분리하는 작업이 필요하다. 하지만 y를 보면 데이터가 한쪽으로 편향되어있다. 7 : 3으로 자르면 평가용 정답 데이터에는 2만 들어갈 것이다. 그렇다면 좋은 학습 방법이 아니다. 따라서 우리는 y를 섞어서 분리하는 과정이 필요하다
그래서 새롭게 배우는 방법인 train_test_split( ) 함수를 사용해서 분리하는 방법이다.
train_test_split( ) 함수를 사용하기 위해서는 sklearn에서 import해서 사용해야 한다.
이 함수를 설명하면 1, 2번째 매개변수로 X, y 데이터를 넣으면 각 데이터를 훈련용 데이터, 평가용 데이터로 나누어준다. 각 나누어진 데이터들은 1, 2번째(X_train, X_test) 3, 4번째(y_train, y_test)로 대입된다.
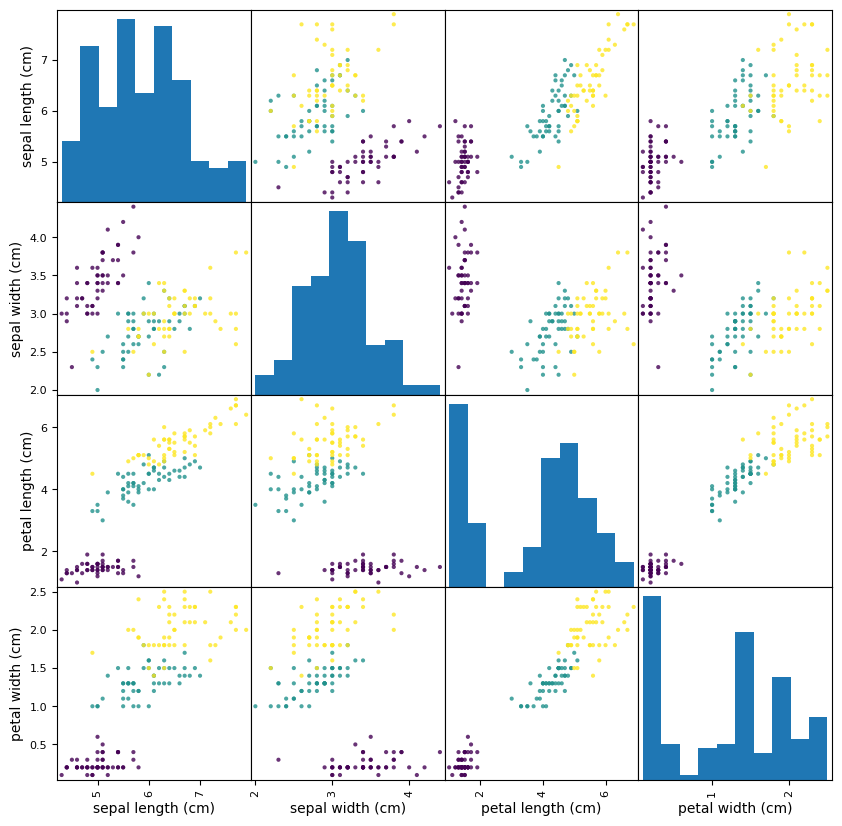
5 - 3. 행렬 산점도
# 산점도 행렬(scatter matrix) : 변수간의 관계를 한꺼번에 보기를 제공
import matplotlib.pyplot as plt
pd.plotting.scatter_matrix(X,
figsize=(10, 10),
c = y, # 정답에 따라서 컬러를 구분하겠다
alpha = 0.8)
plt.show()행렬 산점도는 pandas를 이용해서 만들 수 있다. plotting.scatter_matrix를 사용해서 만들 수 있는 데 사용된다. 산점도 행렬은 각 컬럼들의 상관관계를 알 수 있다. 사용되는 매개변수를 설명해 보겠다. X의 데이터로 산점도의 기준인 축?으로 사용하겠다는 것이고, figsize는 그래프를 그릴 도화지? 면적의 크기를 정하는 것이다. 10, 10으로 정사각형 모양으로 만들어주었다. c = y는 c는 color이고 y를 적은 것은 y의 값에 따라 색깔을 다르게 해 주겠다는 것이다. alpha는 투명도를 의미하는데 해당 산점도는 데이터끼리 겹치기 때문에 투명도를 주어서 겹침정도를 확인해야 한다. alpha값이 1에 가까울수록 불투명해지고 0에 가까워질수록 투명해진다.
6. 모델 학습
knn_model.fit(X_train, y_train)fit( ) 함수를 사용해서 knn모델을 train 데이터로 학습시킨다.
7. 평가
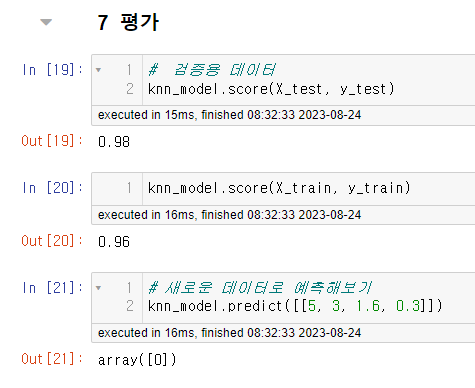
test 데이터와 train 데이터를 평가해보았을 때 test 데이터의 정확도가 더 높았다. 딱히 상관없다. test 데이터의 정확도가 높으면 된다.
'머신러닝' 카테고리의 다른 글
| [머신러닝] 결정 트리 버섯데이터 실습 (One-hot 인코딩) (0) | 2023.08.25 |
|---|---|
| [머신러닝] 머신러닝 Decision Tree(결정 트리) 모델 (0) | 2023.08.24 |
| [머신러닝] KNN모델과 지도학습(일반화, 과대적합, 과소적합) (0) | 2023.08.23 |
| [머신러닝] BMI 실습 (지도학습) (1) | 2023.08.22 |
| [머신러닝] 머신러닝이란 (0) | 2023.08.21 |