
결정트리 모델로 버섯 데이터를 식용과 독성으로 구분하다.
1. 문제정의
버섯의 22가지 특징을 활용해서 식용 / 독성을 분류한다.
2. 데이터 수집
import pandas as pd
mushroom = pd.read_csv("./data/mushroom.csv")
mushroom.head(10)
# 행(8124), 열(특성22개, 정답1개)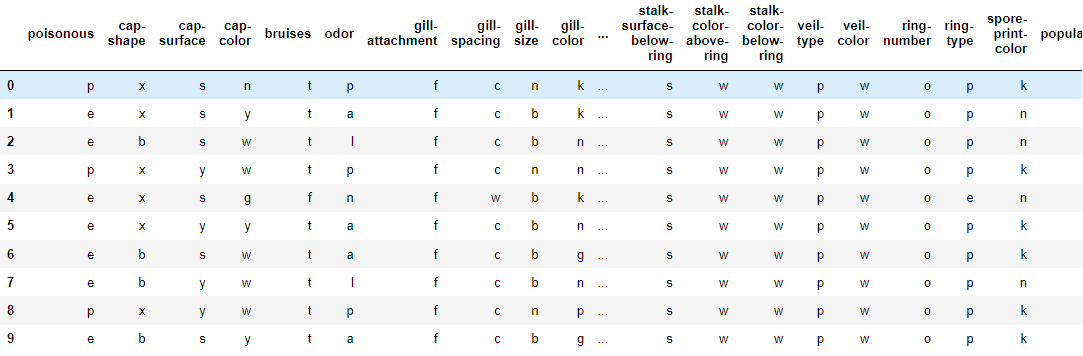
버섯 데이터를 확인해보면 데이터가 수치형이 아니라 문자형으로 되어있는 것을 알 수 있다.
첫 번째 컬럼인 poisonous는 정답데이터이다. e : 식용, p : 독성이다. 따라서 이후에 데이터를 나눌 때 문제 데이터(X)는 첫 번째 컬럼을 제외한 나머지 컬럼이고, 정답 데이터(y)는 첫 번째 컬럼만 있으면 된다.
3. 데이터 전처리
데이터 전처리 단계에서는 결측치와 이상치를 확인해야한다. 하지만 이상치를 확인할 때 사용하는 describe 함수는 수치형 데이터일 때만 의미가 있기 때문에 결측치만 확인해보겠다.

보면 데이터에 null 값이 없다. 따라서 결측치는 없다
4. 탐색적 데이터 분석
현재 데이터에 수치형 자료가 없기 때문에 시각화하기 까다롭다. 따라서 이후에 수치형 자료로 변환하는 과정 이후에 알고리즘을 시각화 하는 과정을 이후의 새로운 글에서 설명할 예정이다.
5. 모델 선택 및 하이퍼 파라미터 튜닝
5 - 1. 모델 불러오기
# Decision Tree 모델 불러오기
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()sklearn.tree에서 결정트리 분류 모델을 불러온다. 그리고 tree_model 변수에 대입한다.
5 - 2. 데이터 나누기
데이터를 나누는 단계에서 문제 데이터와 정답 데이터로 분리해야 한다. 위에서 언급했듯이 첫 번째 컬럼만 정답데이터이고 나머지 컬럼은 문제데이터이기 때문에 인덱싱으로 나누어준다.
# 문제데이터
X = mushroom.iloc[:, 1:]
X
# 정답데이터
y = mushroom["poisonous"]
y

우리는 문제 데이터를 Encoding으로 문자 데이터를 숫자 데이터로 변환하는 과정이 필요하다. 여기서 사용 되는 Encoding 방법이 2가지가 있는데 Label 인코딩과 One-hot 인코딩이다.
5 - 2 - 1. Label 인코딩
라벨 인코딩은 하나의 값에 하나의 숫자를 대입해서 인코딩하는 방식이다. 별로 사용되지 않는 방식이다. 그 이유는 사용자가 값을 직접 변경함에 있어서 사용자의 개입이 들어가고, 원래 문자가 가지고 있던 의미는 사라지고 사용자가 임의로 값을 부여하기 때문에 데이터에 영향을 미칠 수 있기 때문에 잘 사용되지 않는 방법이다.
일단 해당 컬럼이 어떤 종류의 데이터를 가지고 있는지 unique 함수를 사용해서 알아낸다.

해당 컬럼은 6가지 종류로 이루어진 데이터이다. 이제 각 문자에 숫자를 대응해서 변환해주면 된다.

5 - 2 - 2. One-hot 인코딩
주로 사용하는 인코딩 방식이다. 컬럼이 가지고 있는 데이터만큼 컬럼을 생성한다. Label인코딩과 다르게 해당 데이터가 있으면 1, 없으면 0으로 표시된다. 컬럼이 가지고 있는 데이터만큼 컬럼을 생성하기 때문에 데이터가 늘어나는 현상이 생긴다.
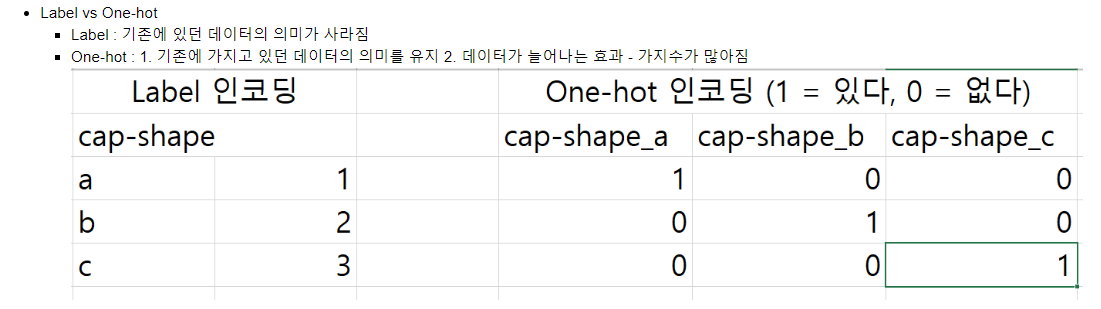
One-hot 인코딩은 그림 7과 같이 컬럼이 문자 데이터의 종류의 개수만큼 생긴다. 데이터가 a인지 b인지 c인지 각각 구별하기 때문에 데이터가 늘어나는 것이다.
# One-hot 인코딩을 진행해주는 함수는 pandas가 가지고 있는 pd.get_dummies(대상)
X2 = X.copy()
X_onehot = pd.get_dummies(X2)
X_onehot.head(5)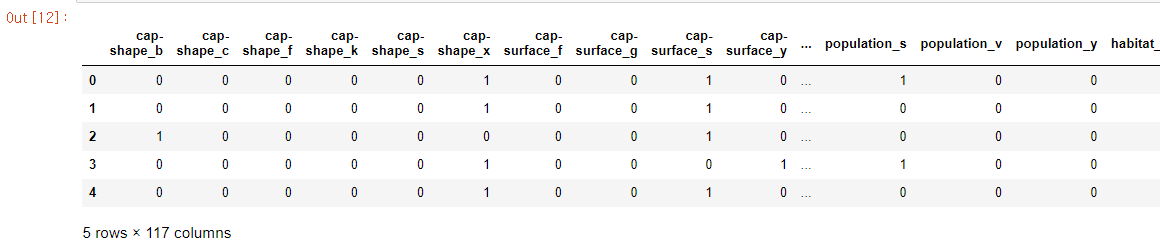
One-hot 라벨링은 pandas의 get_dummies함수를 사용하면 된다. X2를 X의 copy해서 만드는 이유는 기존에 있는 X의 데이터를 보존하기 위해서이다. X2는 그대로 X의 데이터가 복사된 것이다. X와 X2는 서로 독립적인 변수이고 서로 영향을 줄 수 없다. 안의 값만 같은 서로 다른 변수인 것이다. One-hot 라벨링을 하였기 때문에 컬럼의 개수도 확연히 늘어난 것을 볼 수 있다.
5 - 3. 훈련과 평가 데이터 나누기

from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_onehot, y, test_size=0.3)우리는 아직 일반적인 방법으로 데이터를 문제데이터 정답 데이터로 분리하는 방법만 알고있다. 그렇기 때문에 일단 저번에 배운 sklearn.mode_selection의 train_test_split 함수를 사용할 것이다.
하지만 이 방법에는 문제가 있다. 이 경우에는 train데이터로 학습하고 test 데이터로 정답을 확인하고 결과가 마음에 들지 않으면 하이퍼 파라미터 튜닝을 반복한다. 이러면 결국엔 test 데이터로 학습한 것과 다름이 없게되서 결국 과대적합 현상이 발생한다.
그래서 다음 글에서 이 문제점을 보완하는 교차검증(Cross validation) 방식을 설명할 것이다.
6. 학습
tree_model.fit(X_train, y_train)과정 5에서 X와 y를 train과 test로 분리했다. 이 데이터를 가지고 만들었던 모델을 학습시켜야 한다. 모델을 학습시킬 때 사용하는 함수는 fit( )이다.
7. 평가
기존의 방법으로 검증을 한다면 score( )함수를 사용하면 된다.
일단 학습데이터로 검증을 해보면 1.0이 나온다.
tree_model.score(X_train, y_train)
# 보통 1.0 -> 과대적합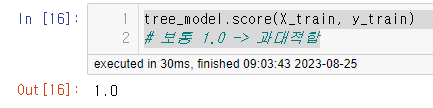
test 데이터로 검증을 해보면
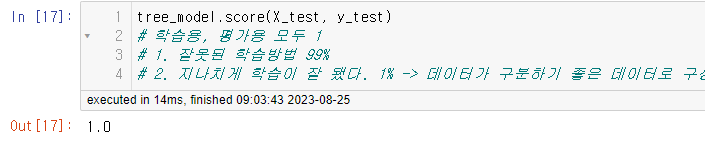
스코어 값이 1이 나온다. 99% 확률로 학습 방법이 잘못된 것이다. 현재 우리는 하이퍼 파라미터를 적용해서 결정트리의 깊이를 제한해주지 않았다. 또한 나머지 파라미터들도 설정하지 않았기 때문에 이러한 결과가 생긴 것이다.
다음 글에서 알고리즘 시각화, 교차검증, 특성 선택과 같은 개념들을 배워서 모델의 성능을 높이도록 하겠다.
'머신러닝' 카테고리의 다른 글
| [머신러닝] 교차검증 (cross_val_score) (0) | 2023.08.28 |
|---|---|
| [머신러닝] 알고리즘 시각화 (graphviz) (0) | 2023.08.25 |
| [머신러닝] 머신러닝 Decision Tree(결정 트리) 모델 (0) | 2023.08.24 |
| [머신러닝] KNN모델 - Iris 붓꽃 품종 분류 실습 (일반화, 과대적합, 과소적합) (0) | 2023.08.24 |
| [머신러닝] KNN모델과 지도학습(일반화, 과대적합, 과소적합) (0) | 2023.08.23 |