
지도학습의 분류 학습으로 머신러닝 Decision Tree 모델을 배우다.
학습목표
- Decision Tree 알고리즘 이해
- Label Encoding, One-hot Encoding을 이해
- 교차 검증 기법을 이해
Encoding이란 범주형 데이터, 즉 문자 데이터를 수치형 데이터로 변환하는 것이다. 반대로 수치형 데이터를 범주형 데이터로 변환하는 것은 Binning이다. 교차 검증 기법은 모든 데이터를 나눠서 학습하고 검증하는 방법이라고 알고 있으면 된다.
1. Decision Tree(결정 트리) 모델
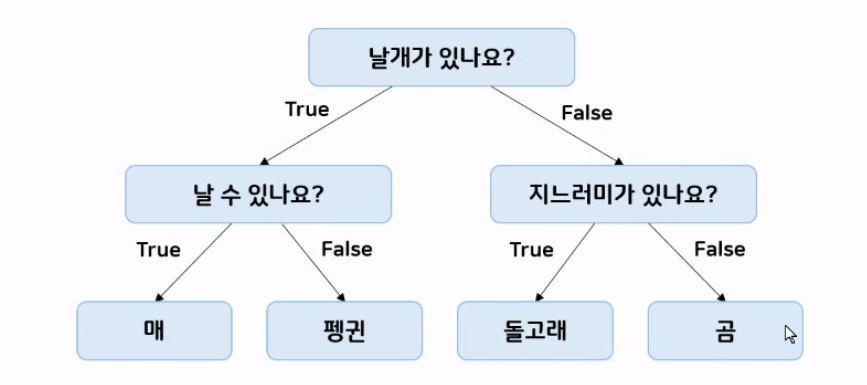
Decision Tree(결정트리) 모델은 위의 예시(그림 1)를 보면 이해하기 쉽다. 첫 번째로 모든 데이터를 잘 분류할 수 있게 질문을 한다. 그 질문에 맞게 데이터를 분류하고 또 질문해서 분류를 하다 보면 결과가 나오게 되는 머신러닝 모델 분류 방법이다. 결정을 해야 하는 상황이 최상단에 있고 하단에 경우의 수나 새로운 질문으로 가지가 뻗어 나가는 형태이다. 아래로 향하는 나무 모양이다. Tree를 만들기 위해 질문에 예/ 아니오로 답할 수 있는 질문을 반복하며 학습하여 클래스(정답)를 분류한다. 특정 기준(질문)에 따라 데이터를 구분하는 모델이다.
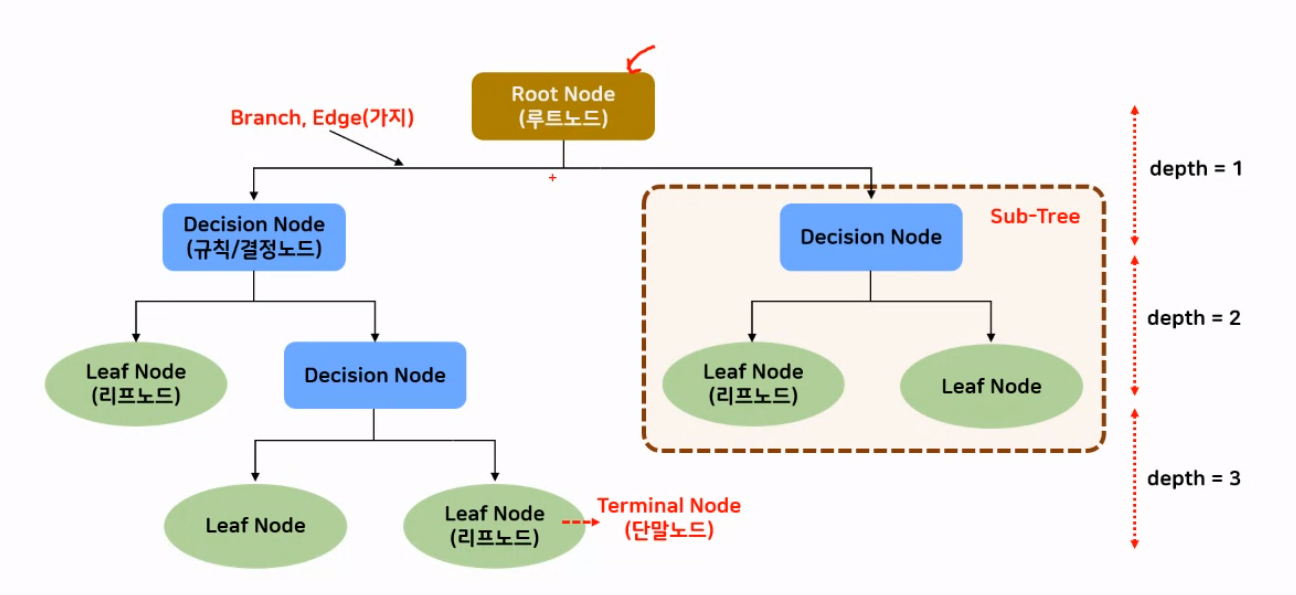
최상단의 첫 번째 질문을 Root Node라고 한다. Root가 뿌리니까 뒤집어진 나무 모양이라고 했던 게 맞다. 각 노드를 잇는 것을 Branch라고 한다. 규칙이나 질문으로 분류하는 것을 Decision Node라고 한다. Leaf Node는 정답이 나오는 노드이다.
Decision Node와 Decision Node 사이를 하나의 depth로 정의하는데 결정트리는 depth가 많을수록 과대적합이 쉽게 일어날 수 있다. 왜냐하면 더 세분화하면서 학습을 하기 때문에 평가할 때는 성능이 저하되는 경우가 있기 때문이다. 그래서 depth는 하이퍼 파라미터로 최대 깊이를 정해줘야 한다.
결정트리의 목표는 정답의 불순도가 낮아지는 방향으로 학습하는 것이다. 불순도가 무엇인지 설명하겠다.
2. 불순도, 순도, 엔트로피

위의 그림 3을 보자. 박스 1, 3은 분리가 잘 되었다. 이러한 경우를 A라고 하겠다. 박스 2는 분리가 잘 되어있지 않다. 이러한 경우를 B라고 하겠다. 결정 트리는 박스 1, 3과 같은 결과를 목표로 한다. A의 경우를 분리가 잘 되었기 때문에 불순도가 낮고 순도가 높다고 볼 수 있다. B의 경우는 반대로 불순도가 높고 순도가 낮다고 볼 수 있다.
불순도가 높으면 여러 가지 클래스(정답)가 섞여 있다는 것이다. 반대로 낮으면 거의 하나의 클래스로 이루어져 있다는 것인데 결정트리는 말했듯이 불순도가 낮아지는 방향으로 학습하는 것을 목표로 한다.
엔트로피는 해당 범주 안에 같은 데이터가 얼마나 포함되어 있는지를 의미한다. 불순도가 높을수록 엔트로피는 높다. 순도가 높을수록 엔트로피는 낮다. 따라서 불순도와 엔트로피는 비례관계, 순도와 엔트로피는 반비례관계임을 알 수 있다.
엔트로피 ∝ 불순도
엔트로피 ∝ 1/순도
나는 불순도와 엔트로피의 관계를 처음에 이해하기 어려워서 따로 검색해서 찾은 결과↓
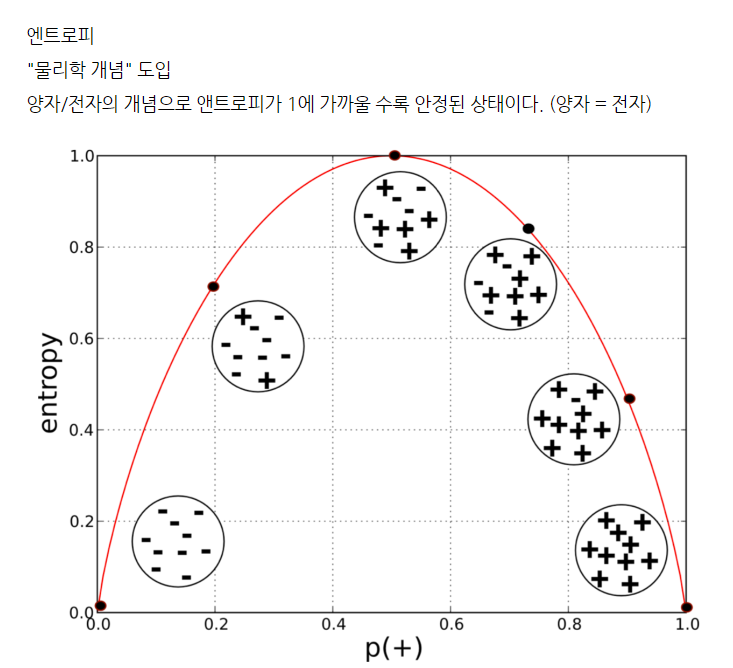
양자와 전자로 확인하면 가장 안정할 때 엔트로피가 높으니까 엔트로피와 불순도의 관계가 이해되었다.
불순도를 수치화해서 만든 지표에서 사용되는 게 지니 불순도, 엔트로피이다.
지니 불순도는 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 의미한다. 불순한 정도를 의미하는데 지니 불순도값이 낮아지는 쪽으로 학습해야 한다. 지니 불순도의 범위는 0 ~ 0.5 사이 값을 가지고 불순도가 0에 가까울수록 잘 분류된 것이다. 불순도가 0.5라면 데이터가 5:5 비율로 섞여서 분류된 것이다. 그럼 분류가 잘 되지 않았다는 것.
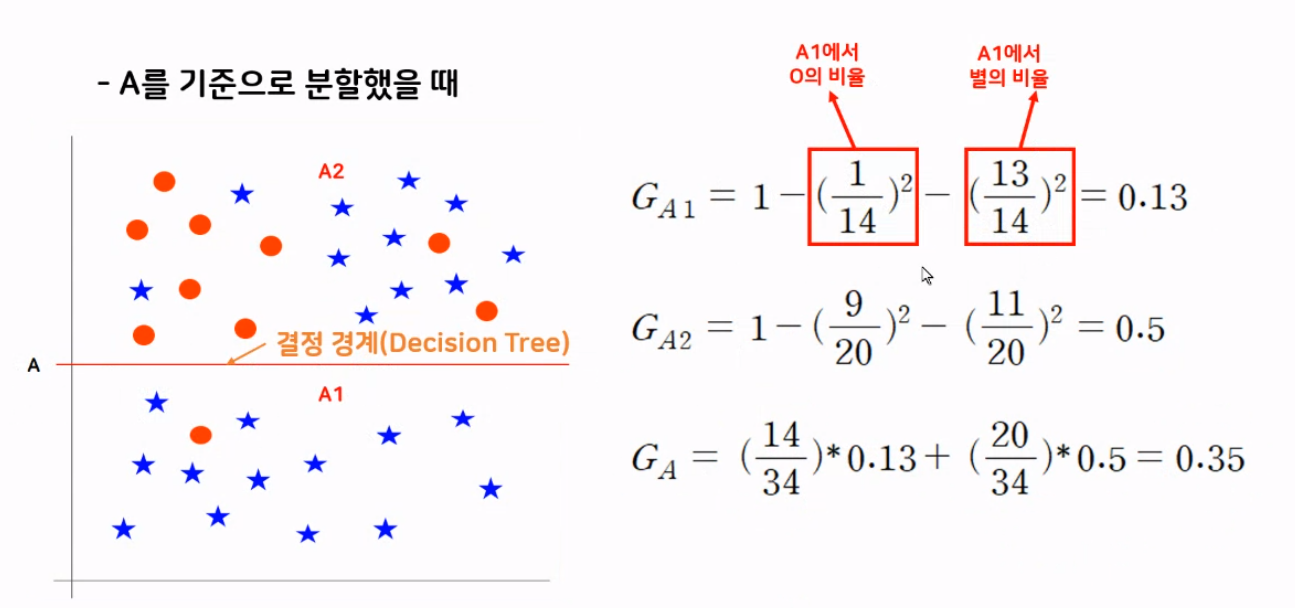
지니 불순도를 계산하는 방법은 현재 사용하지 않을 것이긴 하지만 알아두면 좋다. 해당 영역의 지니 불순도를 구하기 위해서 1에서 빼주는 것부터 시작한다. 무엇을 빼냐 함은 해당 영역에서 ( 특정 데이터 개수/해당 영역에 속한 모든 데이터개수)의 제곱을 빼주면 된다. 현재 예시 그림에선 빨간 원과 파란 별, 2가지 밖에 없기 때문에 1에서 2가지만 빼는데 여러 가지가 되면 똑같은 방법으로 1에서 빼주면 된다. 그럼 해당 영역에 지니 불순도가 구해지고 각 영역의 지니 불순도를 구하면 전체 영역의 지니 불순도도 구할 수 있다. (특정 영역 데이터 개수/전체 영역 데이터 개수) * (해당 영역의 지니 불순도)로 각 영역을 계산해서 합하면 전체 영역의 지니 불순도를 구할 수 있다.
3. Decision Tree의 하이퍼 파라미터, 사전 가지치기

criterion의 기본값은 gini인데 이건 지니 불순도를 뜻한다. 상황에 맞게 알아서 선택하면 된다. 사전 가지치기 작업이 거의 필수적으로 필요하다. 그렇지 않으면 과대적합 현상이 일어날 확률이 높다. max_depth로 트리의 최대 깊이를 정해주지 않으면 거의 무조건 과대적합 현상이 일어난다. 사전 가지치기 작업으로 정한 수치 안에서 멈춰버리기 때문에 과대적합을 제어할 수 있다.
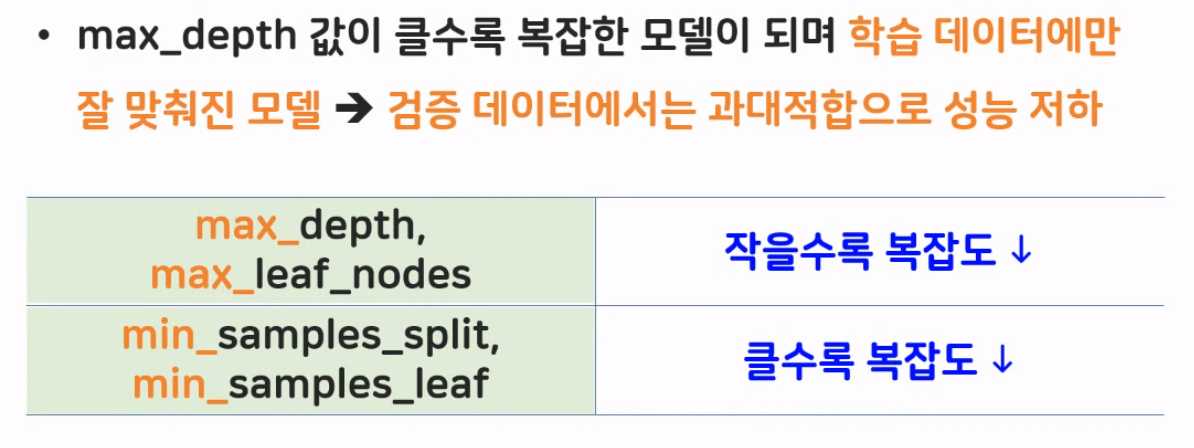
외우기 쉽게 앞에 max가 붙은 파라미터는 작을수록 복잡도(학습량)가 낮게 된다. 반대로 min이 붙은 파라미터는 클수록 복잡도(학습량)가 낮게 된다. 복잡도를 낮춰야 하는 이유는 과대적합을 제어하기 위해서는 학습량을 줄이는 것이 해결책이기 때문이다.
4. Decision Tree의 장·단점

1, 2, 3번째가 장점이고 4, 5번째가 단점이다. 2번 장점은 모델을 학습시킬 때 애초에 질문(규칙)을 기준으로 분류되기 때문에 데이터 전처리 과정이 필요하지 않다.
'머신러닝' 카테고리의 다른 글
| [머신러닝] 알고리즘 시각화 (graphviz) (0) | 2023.08.25 |
|---|---|
| [머신러닝] 결정 트리 버섯데이터 실습 (One-hot 인코딩) (0) | 2023.08.25 |
| [머신러닝] KNN모델 - Iris 붓꽃 품종 분류 실습 (일반화, 과대적합, 과소적합) (0) | 2023.08.24 |
| [머신러닝] KNN모델과 지도학습(일반화, 과대적합, 과소적합) (0) | 2023.08.23 |
| [머신러닝] BMI 실습 (지도학습) (1) | 2023.08.22 |