
KNN 모델의 알고리즘을 이해하고 하이퍼 파라미터 튜닝을 배우다.
1. KNN 모델 알고리즘
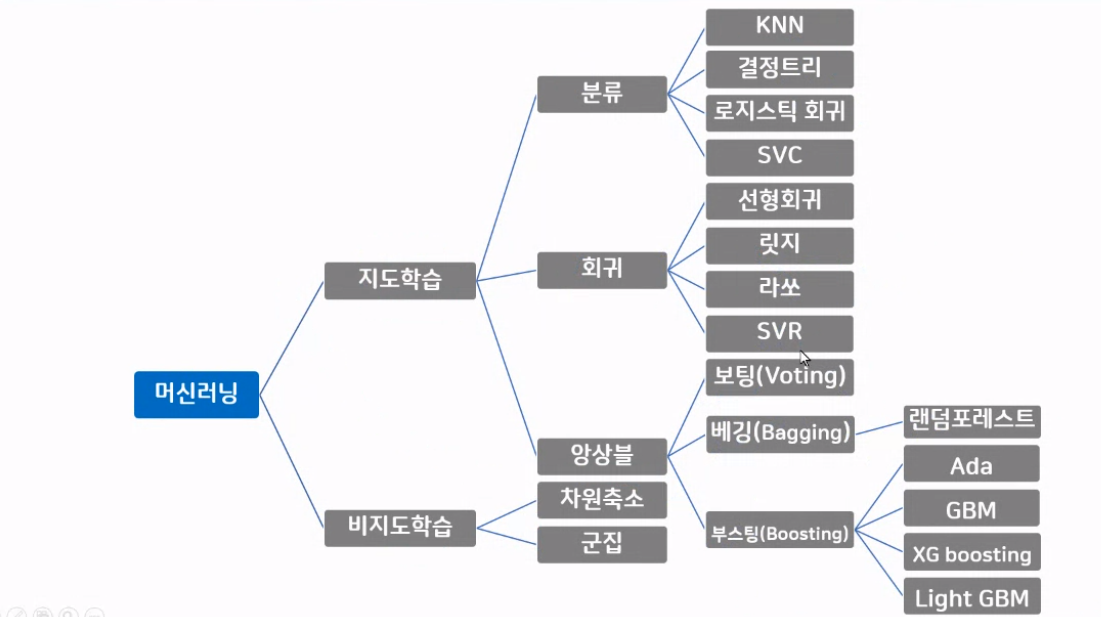
현재 KNN 모델을 공부하고 있다. KNN 모델은 지도학습에서 분류 방법으로 학습하는 머신러닝 모델이다.
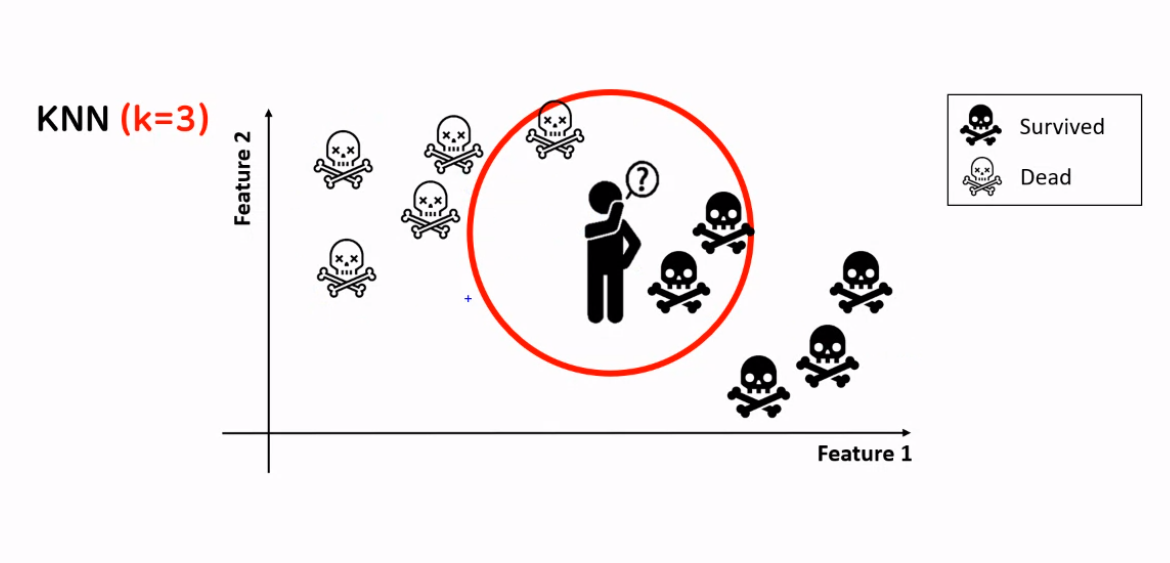
KNN은 K-Nearest Neighbors의 줄임말이다. KNN은 거리기반으로 학습을 하는데 무슨 소리냐면 KNN에서 K는 미지수인데 K값에 따라 가까운 이웃의 수를 결정한다. K가 만약 3이면 주변 3개의 이웃의 데이터를 보고 스스로 예측한다.
KNN 모델은 지도학습의 분류와 회귀, 두 곳 다 사용할 수 있는데 분류에서는 문자형태로 정답이 있기 때문에 이웃 중에서 가장 많은 값으로 예측한다. 회귀는 정답 데이터가 연속된 수치데이터이기 때문에 이웃 값의 평균값으로 예측한다.
knn_model2 = KNeighborsClassifier(n_neighbors=3)KNN 모델을 생성할 때 n_neighbors 매개변수를 사용자가 줄 수 있다. KNN의 하이퍼 파라미터는 n_neighbors인 것이다.
분류와 회귀에서도 KNN 알고리즘을 사용할 수 있다. 분류에서는 이웃중에서 가장 많은 값으로 예측한다.
회귀에서는 이웃 값의 평균 값으로 예측한다. 그래서 KNN 모델을 사용할 때 이웃의 수(n_neighbors)를 적절하게 정해줘야 한다.
KNN 모델의 장점은 이해하기 쉽고 조정 없이도 좋은 성능을 발휘하는 기초 모델이다.
KNN 모델의 단점은 훈련 데이터 세트(특성, 데이터 수)가 크면 예측이 느려진다. 거리를 측정하기 때문에 데이터의 스케일 조정이 필요하다.
2. 일반화, 과대적합, 과소적합
위 3개의 용어는 모델의 신뢰도를 측정하고 성능을 확인하기 위한 개념이다. 따라서 n_neighbors인 최적점의 하이퍼 파라미터값을 찾기 위해 사용되는 개념이다.
2 - 1. 일반화
일반화는 train 데이터로 학습한 모델이 test 데이터에 대해서도 정확히 예측하는 현상을 말한다. 일반화의 성능이 가장 좋은 쪽으로 가는 것이 머신러닝의 목표이다.
2 - 2. 과대적합
하지만 모델을 학습시킬 때 너무 과하거나 너무 신경을 안 쓰면 생기는 문제들이 바로 과대적합과 과소적합이다. 예를 들어 설명해 보겠다. 머신러닝 모델에게 "공"에 대해 학습시키려고 한다.
1 번째 경우 나는 모델에게 축구공의 특징을 학습시켰다.
- 공은 둥글다.
- 흰색과 검은색으로 이루어져 있다.
- 표면이 육각형과 오각형으로 이루어져 있다.
이런 규칙, 특징을 공이라고 모델에게 학습시켰더니, 이렇게 학습받은 모델은 축구공은 공으로 인지하지만 농구공, 볼링공등 다르게 생겼지만 공인 것들은 공이라고 인지하지 못한다. 이러한 상황을 과대적합이라고 한다.
과대적합은 train 데이터에 너무 과도하게 학습되어 있어서 test 데이터에서는 예측 성능이 저하되는 현상이다.
예시에서는 train 데이터는 축구공의 특징이고, test데이터는 다른 공들인 농구공, 볼링공이다.
과대적합의 경우에는 train 데이터에서만 성능이 좋다.
2 - 3. 과소적합
반대로 모델에게 단순한 규칙과 특징을 학습시키면 생기는 문제는 과소적합이다. 똑같은 예시로 "공"에 대해 학습시키려고 한다. 이번에 모델에게 학습시킬 규칙은 다음과 같다.
- 공은 둥글다
다음 규칙만 모델에게 학습시키고 정확도 검사를 하면 학습을 모델링을 너무 간단하게 해서 성능이 저하되는 현상이다.
과소적합의 경우 train데이터, test데이터 모두 성능이 좋지 않다.
2 - 4. 해결
모델을 학습시킬 때 과대적합 현상이 일어났다면 모델 학습을 너무 많이 한 것이다. 과소적합은 반대로 너무 적게 학습한 것이다. 따라서 적절한 학습양이 중요하다. 일반적으로 데이터의 양이 많으면 일반화에 도움이 된다. 그리고 한쪽으로 편중되지 않고 다양성을 갖춘 훈련데이터로 모델을 학습시키면 일반화에 도움이 된다. 이후에는 규제를 통해 모델의 복잡도를 적정선으로 결정할 수 있다.

해당 그래프의 x축은 모델 복잡도인데 이것은 학습량으로 생각하면 된다. 모델에게 학습을 많이 시키면 오른쪽으로, 덜 시키면 왼쪽으로 간다. 과대적합은 훈련데이터에서만 성능이 좋은 현상이 일어난다 했고 과소적합은 훈련데이터, 평가데이터 두 곳에서 score가 낮아서 성능이 안 좋다. 그래서 우리는 일반화, 즉 평가데이터에서 성능이 가장 좋은 부분의 하이퍼 파라미터를 구해야 한다.
'머신러닝' 카테고리의 다른 글
| [머신러닝] 결정 트리 버섯데이터 실습 (One-hot 인코딩) (0) | 2023.08.25 |
|---|---|
| [머신러닝] 머신러닝 Decision Tree(결정 트리) 모델 (0) | 2023.08.24 |
| [머신러닝] KNN모델 - Iris 붓꽃 품종 분류 실습 (일반화, 과대적합, 과소적합) (0) | 2023.08.24 |
| [머신러닝] BMI 실습 (지도학습) (1) | 2023.08.22 |
| [머신러닝] 머신러닝이란 (0) | 2023.08.21 |