
sklearn.neighbors 모델을 만들고 지도학습시켜서 머신러닝 실습을 하다.
머신러닝의 학습 단계는 7단계로 구성되어 있다. 각 단계를 설명하면서 실습도 함께 진행하려고 한다.
- 문제 정의
- 데이터 만들기
- 데이터 전처리
- 탐색적 데이터 분석 (EDA)
- 모델 생성(선택) 및 하이퍼 파라미터 정의 (튜닝)
- 모델 학습
- 정확도 평가
1. 문제 정의
학습단계 중 1단계인 문제정의에 대해 설명하겠다. 문제 정의 단계는 문서작성하는 단계와 비슷하다.
- 목적 : 머신러닝을 통해서 어떤 문제를 해결할 것인지? -> 비만을 판단하는 모델 만들기
- 학습 선택 : 지도학습 vs 비지도학습 vs 강화학습 -> 지도학습
- 지도학습에서 분류 vs 회귀 -> 분류 (저체중, 정상, 과체중, 비만 등)
- 결론 : 비만을 판단하는 모델 만들기 -> 지도학습(분류)
이러한 과정을 통해 내가 어떤 목적을 가지고 머신러닝 모델을 만들고 어떤 학습 방법을 통해 모델을 학습시킬 것인지도 정해야 한다.
2. 데이터 수집
- 기존에 수집된 데이터 파일 활용 (CSV, XML, JSON)
- Database에 저장된 데이터 활용
- Web Crawling (유튜브, SNS, 블로그 등)
- IoT 센서를 통한 수집
- 설문조사

2단계 데이터 수집 과정에선 질 좋은 데이터를 수집해야 한다. 데이터와 모델, 둘 중 하나라도 쓰레기라면 결과물은 쓰레기가 나오게 된다. 쓰레기가 나오지 않게 하기 위해서 좋은 데이터를 수집하고 사용해야 한다.
이번 실습에서는 csv 파일에 담겨 있는 데이터를 사용할 것이다. 이 csv 파일 안에는 500명의 성별, 키, 몸무게, 비만 등급 정보가 담겨있다. 키, 몸무게로 비만등급을 평가한다. 키와 몸무게로 비만등급을 평가하는데 비만등급은 Label로 정답 데이터이다. 따라서 나중에 Height와 Weight가 X가 되고 Label은 y가 된다.
3. 데이터 전처리
데이터를 실제로 사용하기 전에 사용할 데이터에 문제가 없는지 점검해야 한다.
- 결측치(null) 처리 : 비어있는 데이터를 채워주기
- 이상치 처리 : 정상적인 범위를 벗어난 데이터를 알맞게 수정하기
- 특성공학 ↓
- 단위변환 (Scaling)
- 새로운 속성 추출 (Transform)
- 범주형 → 수치형 (Encoding)
- 수치형 → 범주형 (Binning)
3 - 1. 결측치 확인하기

결측치를 확인하기 위해서는 info( ) 함수를 사용한다. info( ) 함수를 사용하는 데이터가 데이터 프레임 형태여야 사용할 수 있다.
결측치가 있는지 없는지 확인하기 위해서 Non-Null Count 컬럼을 확인하면 된다. 현재 데이터의 개수는 500개이다.
500 non-null에서 non-null 앞의 숫자가 데이터의 개수와 같으면 현재 데이터에 결측치는 없다는 것이다.
3 - 2. 이상치 확인
정상 범위를 벗어난 이상치를 찾기 위해 사용되는 함수는 describe( ) 함수이다.
이 함수도 마찬가지로 사용하는 데이터의 형태가 데이터 프레임 형태여야 사용할 수 있다.
이 함수의 결과는 다음과 같다.

- count : 데이터의 수
- mean : 평균
- std : 표준편차
- min : 최솟값
- 25% : 1 사분위수
- 50% : 중앙값, 2 사분위수
- 75% : 3 사분위수
- max : 최댓값

25%, 50%, 75%의 분위수를 설명하자면 위 그림처럼 어떤 데이터를 4 등분하는 걸 4 분위수라고 한다.
각 등분하는 부분을 1 사분위수 2 사분위수 3 사분위수라 고한다.
이 과정에서 생각해야 될 것은 다음과 같다.
- min, max 확인하기 -> 최솟값, 최댓값이 정상적인 수치가 아닌지 확인한다
- 평균(mean), 중앙값(50%) 확인하기 -> 두 수치가 비슷한지 확인한다.
- 과정 2에서 두 수치가 비슷하지 않을 경우, min ~ max까지의 간격에서 데이터들이 고르게 분포되어 있는지 확인한다.
4. 탐색적 데이터 분석 (EDA)
- 기술통계, 변수간 상관관계
- 시각화 : pandas, matplotlib, seaborn
- 사용할 특성 선택 (Feature Selection) : 필요한 데이터, 의미 있는 데이터만 사용해서 시간 절약
데이터를 시각화하고 y별로 데이터가 잘 나뉘어있는지 확인한다.
현재 우리의 데이터의 y는 비만도(Label)이기 때문에 데이터의 Label 칼럼을 색인해야 한다.
비만도 등급의 종류를 확인해야 하므로 unique( ) 함수를 사용한다.
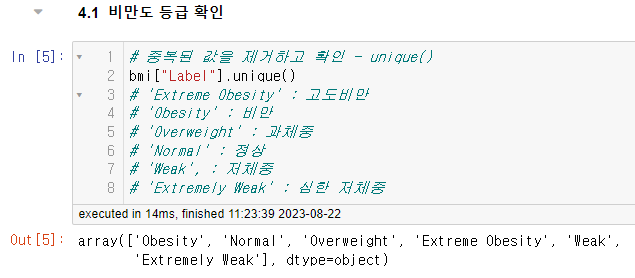
가진 데이터들을 시각화해서 데이터들이 고르게 분포되어있는지 이상치가 없는지 확실하게 확인해 준다.
우리는 키와 몸무게를 x축 y축으로 하고 비만도 종류에 따라 분포되어 있는 산점도 그래프를 그릴 것이다.
비만도 등급에 따라 그리는 그래프는 모두 같은 구조이므로 그래프를 그리는 걸 함수형태로 만들어서 사용한다.
4 - 1. 그래프 그리는 함수 생성
import matplotlib.pyplot as plt
def myScatter(label, color) :
bol = bmi["Label"] == label
data = bmi.loc[bol]
plt.scatter(data["Height"], data["Weight"],
color = color, label = label)사용하기 전에 matplotlib.pyplot을 불러오고 함수를 만든다. 비만도 종류의 이름과 색깔로 그래프에서 구별해야 하기 때문에 그 두 가지를 매개변수로 받아준다.
4 - 2. 전체 그래프 그리기
plt.figure(figsize=(12, 8))
myScatter('Obesity', "red")
myScatter('Normal', "blue")
myScatter('Overweight', "black")
myScatter('Extreme Obesity', "orange")
myScatter('Weak', "yellow")
myScatter('Extremely Weak', "lightgreen")
plt.xlabel("Height")
plt.ylabel("Weight")
plt.legend()
plt.show()
현재 데이터를 가지고 산점도 그래프를 그린 모습이다. 빨간색 원 안에 있는 파란색 점은 Obesity여야 하는데 Normal이다.
이상치라는 소리다. 따라서 우리는 해당 이상치를 수정해야 한다. 해당 데이터의 Label을 Normal에서 Obesity로 수정해야 한다.

파란색은 Normal이니까 Label이 Normal인 컬럼을 불리언 색인으로 걸러주고 해당 데이터의 Height가 원래는 153인지 알 수 없지만 선생님의 빠른 수업 진행을 위해 153으로 했다. 원래 같으면 부등호로 범위를 좁혀가면서 찾아가야 할 것 같다.
아무튼 Height가 153인 데이터까지 걸러주면, 인덱스 231번째 데이터가 Obesity여야 하는데 Normal인 것을 볼 수 있다.
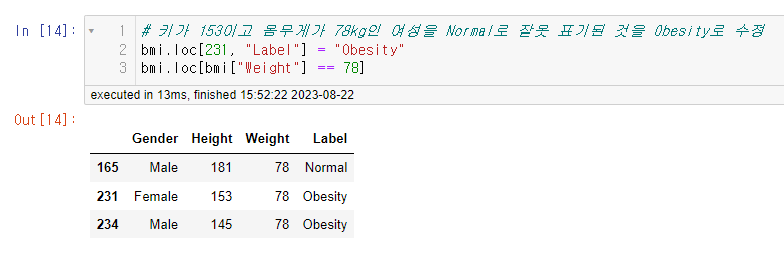
해당 인덱스를 알고 있으니 인덱스로 색인해서 Label을 Obesity로 수정해 준다. 그리고 다시 확인해 보면 정상적으로 Obesity로 변경된 것을 확인할 수 있고 산점도 그래프를 다시 만들어서 확인해 보면
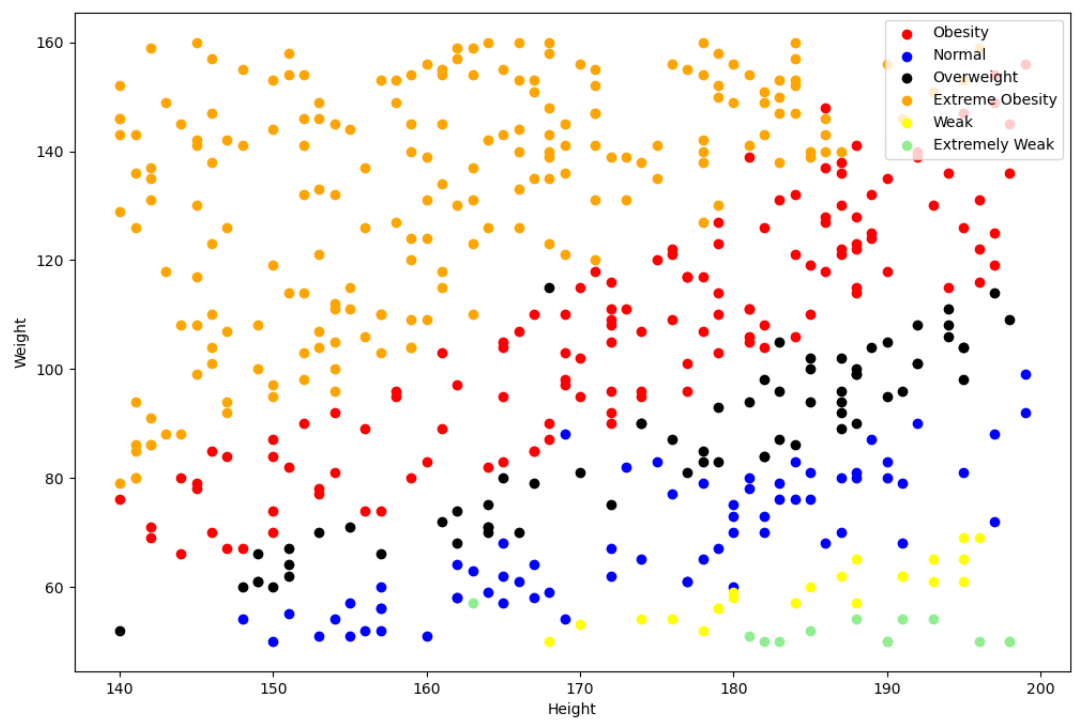
원래 파란색 점이 있던 자리가 빨간색 점으로 변경된 것을 확인할 수 있다. 이런 식으로 개발자가 직접 결측치, 이상치 데이터를 수정하면서 모델 학습에 도움을 줄 수 있다.
5. 모델 선택 및 하이퍼 파라미터 튜닝
드디어 머신러닝의 모델을 불러와서 학습시킬 준비를 하면 된다. 목적에 맞는 적절한 모델을 선택해야 한다.
하이퍼 파라미터 : 모델의 성능을 개선하기 위해 사람이 직접 넣는 parameter
5 - 1. 머신러닝 모델 불러오기
# 머신러닝 모델 불러오기
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier()5 - 2. 문제 데이터와 정답 데이터로 분리하기

일단 수집한 데이터를 문제 데이터 X와 정답 데이터 y로 분리한다. 여기서 X는 Height와 Weight이고, y는 Label이다.
머신러닝 모델은 문제와 정답이 주어지고 학습을 하고 학습한 이후에 검증, 평가를 하기 때문에 문제데이터와 정답 데이터
각각에서 훈련용 데이터 : 평가용 데이터 = 7 : 3의 비율로 나누어준다.
# 문제 : Height, Weight
X = bmi.loc[:, "Height":"Weight"]
X
# 정답 : Label
y = bmi.loc[:, "Label"]
yX_train = X[:350]
X_test = X[350:]
y_train = y[:350]
y_test = y[350:]
print("훈련용 문제 : ", X_train.shape)
print("평가용 문제 : ", X_test.shape)
print("훈련용 정답 : ", y_train.shape)
print("평가용 정답 : ", y_test.shape)
6. 모델 학습
knn_model.fit(X_train, y_train)
# X 데이터(키, 몸무게)를 통해서 y 데이터(비만도 등급)의 규칙을 학습을 통해 찾음머신러닝 모델을 학습할 때 사용하는 훈련용 train 데이터로 fit( ) 함수를 사용해서 모델을 학습한다.
7. 평가
- model.predict(X_test)
- 정확도(Accuracy)
- 재현율(Recall)
- 정밀도 (Precision)
- f1 score
7 - 1. predict( )
마지막 단계인 정확도 평가 단계에서는 모델이 제대로 학습되어 만들어졌는지 확인한다.

사용자가 직접 모델에게 predict( ) 함수를 사용해서 데이터를 입력해서 기댓값이 나오는지 확인할 수 있다.
7 - 2. 정확도 평가 score( )

또 확인하는 방법은 평가용 데이터 test를 사용해서 평가할 수 있다. 이때는 score( ) 함수를 사용하는데 이 함수의 결과는
0 ~ 1 사이값이다. 1에 가까울수록 모델이 적절하게 규칙을 찾아서 올바르게 학습한 것이다.

score함수 안에 test 데이터뿐만 아니라 학습할 때 사용했던 train 데이터를 넣어서 사용하면 당연히 test 데이터의 값보다 높을 것이다. 하지만 train데이터를 넣었을 때의 score값이 더 작을 수도 있기 때문에 train 데이터를 넣는 과정도 필요한 과정이다.
KNN 모델은 특정 값과 가장 가까운 값들과 비교하여 내 값이 어떤 정답을 가져야 하는지 학습한다. 데이터만 입력하면 스스로 학습하는 것처럼 느껴지지만 생각해 보면 사실 당연한 거다. 다양한 양의 데이터를 주고 비교해서 이 값은 이것일 확률이 높다 하고 답을 출력하는 것뿐이라서 지도학습은 흥미가 약간 덜하다. 그래도 개발자의 마음대로 모델을 학습시켜 상황에 맞는 모델을 만들 수 있고 입력하는 데이터의 질이 좋아질 수 있다는 장점 있어서 지도학습이라는 학습 방법이 있는 이유일 것이다.
'머신러닝' 카테고리의 다른 글
| [머신러닝] 결정 트리 버섯데이터 실습 (One-hot 인코딩) (0) | 2023.08.25 |
|---|---|
| [머신러닝] 머신러닝 Decision Tree(결정 트리) 모델 (0) | 2023.08.24 |
| [머신러닝] KNN모델 - Iris 붓꽃 품종 분류 실습 (일반화, 과대적합, 과소적합) (0) | 2023.08.24 |
| [머신러닝] KNN모델과 지도학습(일반화, 과대적합, 과소적합) (0) | 2023.08.23 |
| [머신러닝] 머신러닝이란 (0) | 2023.08.21 |