
페이지의 데이터 수집하는 크롤링을 배우다.
1. '크롤링'이란?
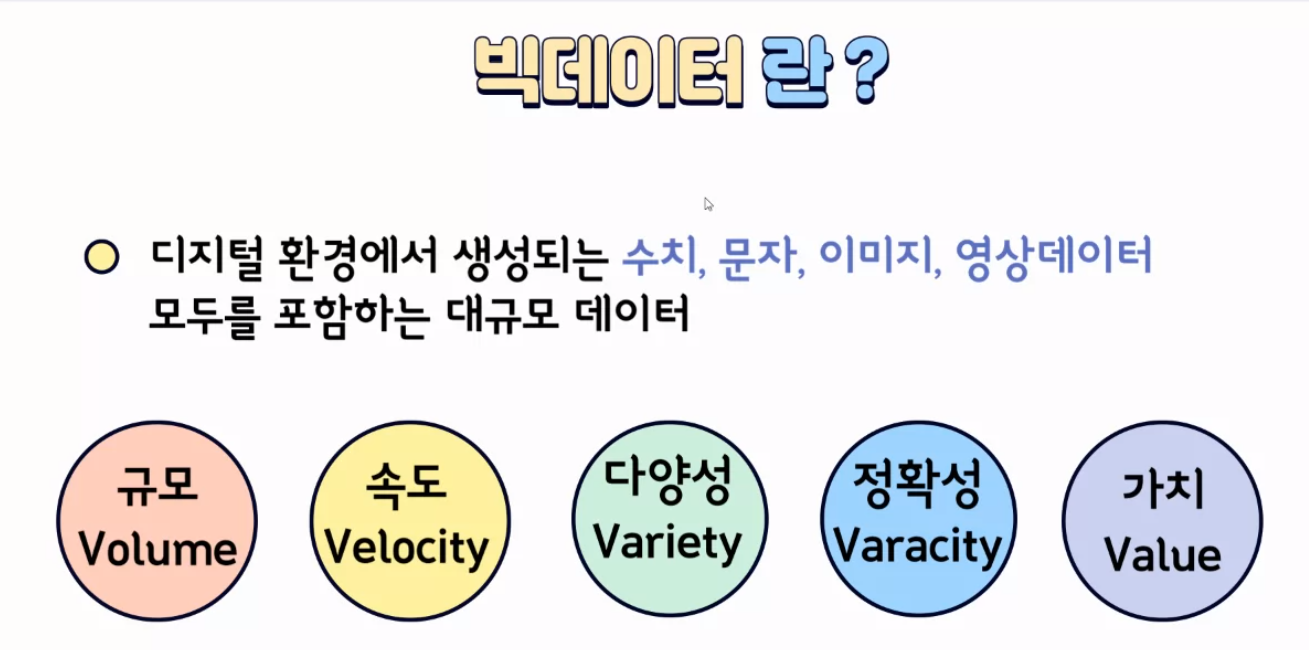
크롤링은 인터넷에서 페이지의 정보를 수집하는 '데이터 수집'하는 행위이다. 인터넷상에는 데이터가 엄청 방대하고 다양(빅데이터)하다. 빅데이터가 존재하는 세상에서 크롤링을 사용하지 않고 데이터를 수집하기에는 너무 번거롭고 효율적이지 못하다. 기존에는 브라우저가 페이지 정보를 요청해서 데이터를 받아와서 페이지를 볼 수 있었는데, 우리는 지금 데이터를 수집해야 하는 입장이니까 크롤링을 통해서 페이지에 데이터를 요청해야 한다. 크롤링으로는 HTML의 태그를 통해서 데이터에 접근할 수 있다. 파이썬 언어를 사용해서 크롤링을 진행한다. 크롤링으로 페이지에 데이터를 요청하기 위해서 requests 라이브러리를 사용해야 한다.
2. 클라이언트와 서버간의 요청과 응답, requests 라이브러리, BeautifulSoup

우리가 지금 데이터를 요청하는 입장이니까 우리가 클라이언트 입장이다. 서버에 데이터를 요청하고 서버가 클라이언트에게 데이터를 주며 응답한다. 데이터를 요청할 때 URL을 사용한다.
서버에게 데이터를 요청하기 위해서 requests 라이브러리를 사용해야 한다.
pip install requests
# 라이브러리 불러오기
import requests as req
# 페이지 정보를 요청하고 응답받으면 역할이 끝필자는 requests 라이브러리를 import 할 때 모듈이 없다고 떠서 'pip install'로 설치해 주었다. url을 통해서 페이지의 정보를 가져온다고 하였다. 그러니까 우리가 페이지의 정보를 가져오려고 할 때마다 페이지의 url을 가져와야 한다.
# 네이버 페이지의 정보 요청 후 응답받기!
url = "https://www.naver.com/"
# url 주소의 페이지 정보를 가져와
res = req.get(url)
res
res의 결과를 보면 Response 200이 나온다. 코드 200은 정상적으로 요청과 응답과정이 이루어진 것이다. 400번대 오류코드는 클라이언트가 서버에게 데이터를 요청할 때 오류가 발생한 것이고, 500번대 오류코드는 서버의 응답에 문제가 있을 때 발생하는 오류코드이다.
# 우리가 요청했던 naver 페이지의 정보 확인
# text : HTML 전부 가져옴
# 태그를 통해서 가져올 정보만 가져오기
res.text
우리가 원하는 응답 받은 데이터를 보기 위해서 text를 사용해서 볼 수 있다. res.text를 사용하면 해당 페이지의 전체 HTML 코드가 결과로 나타난다. 일반적인 HTML 코드처럼 보이지만 사실 이건 문자열 형태이다. 앞에 따옴표가 있다. 문자열 형태로는 컴퓨터가 태그를 인식하지 못하기 때문에 우리는 문자열을 HTML로 변환해야 한다.
이때 사용하는 라이브러리가 BeautifulSoup 라이브러리이다.
# 라이브러리 불러오기
from bs4 import BeautifulSoup as bs
# beautifulSoup 객체화 -> 파싱
# bs(문자열 정보, "파싱 방법")
soup = bs(res_weather.text, "lxml")
soup문자열을 HTML로 바꾸는 과정을 beautifulSoup 객체화 or 파싱이라고 한다. 해당 라이브러리는 매개변수로 문자열정보와 파싱 할 방법을 받는다. 파싱 종류는 다음과 같다.

상황에 맞게 파싱 방법을 선택하면 된다. lxml 방법으로 HTML로 파서 해보겠다.

이제 진짜 우리가 원하는 형태의 데이터 정보가 가져와졌다. url을 통해 문자열이아닌 HTML 형태의 페이지 정보를 가져왔다. 이제 우리가 가져올 정보의 태그를 이용해서 아무 정보가 아닌 특정 정보만 정확하게 가져와야 한다.
3. 태그와 선택자 이용해서 정보에 접근하기
나는 네이버 날씨 페이지에서 현재 날씨 정보에 접근해서 '현재 온도' 데이터를 가져오려고 한다. 접근하기 전에 알아야 할 개념이 있다. 요소, 태그, 콘텐츠, 선택자이다.

요소는 태그와 컨텐츠를 포함하고 있다. 우리는 태그를 이용해서 요소로 접근해야 한다. 해당 데이터가 무슨 태그에 있는지 확인하기 위해서 해당 페이지에서 F12(개발자도구)를 눌러서 커서를 누른 후 해당 데이터를 갖다 대면 무슨 태그에 있는지 확인할 수 있다.

변수 soup에 전체 HTML이 있으니까 거기서 우리가 원하는 콘텐츠를 포함하는 태그를 선택하면 된다. 태그를 선택할 때는 select함수를 사용하면된다. select함수는 매개변수로 ("태그")를 받는다. 우리가 원하는 콘텐츠가 strong 태그 안에 있기 때문에
soup.select("strong")이렇게 하면 된다. 는 아니고 이렇게하면 해당페이지에서 strong 태그들이 전부 리스트형태로 가져와진다. 그래서 우리는 선택자를 이용해서 특정 태그만 선택해서 범위를 줄여서 가져올 콘텐츠만 가져와야 한다. 선택자는 id, class 선택자가 있다. id 선택자는 단 1번만 사용가능하고, class 선택자는 여러 번 사용 가능하다. 그리고 선택할 태그를 포함하는 요소에 콘텐츠를 추출하면 자식 요소의 콘텐츠까지 전부 가져와진다. 이걸 이용해서 우리가 필요로하는 데이터의 태그에 선택자가 없을 경우 또는 가져와야할 콘텐츠의 개수가 여러개라서, 여러개의 콘텐츠를 하나의 바구니에 담는 과정이 필요하면 해당 요소의 부모요소에 선택자가 있는 지 확인하고 있다면 부모요소로 접근을 시작해서 콘텐츠를 가져오면 된다.
콘텐츠를 추출하기 위해서는 (요소.text) 형태로 사용하면 된다. 요소에 text를 사용해야 한다는 것이 중요하다. 아까 말했듯이 select로 가져오면 리스트형태로 가져와진다. 태그를 선택하는 다른 방법이 있는데 바로 select_one 함수이다.select_one 함수를 사용하면 결과로 요소를 반환한다. 반환하는 요소는 요소들 중에 가장 첫 번째, 리스트에서 가장 첫 번째 요소가 반환된다. select_one을 사용할 수 있으면 사용하던가 아니면 select를 사용해서 리스트 인덱싱을 통해 요소로 만들어 사용하는 방법이 있다.
url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EB%82%A0%EC%94%A8"
res_weather = req.get(url)
soup = bs(res_weather.text, "lxml")
# 현재 내가 가져오고자하는 태그에 id, class 값이 없다면 그의 부모태그를 확인한다.
soup.select("div.temperature_text")[0].text부모요소로 div태그가 있고 부모요소에 class 선택자가 있으니까 부모요소로 접근한다. 그리고 자식요소의 콘텐츠로 '현재 온도', '21. 4'가 있다. 우리는 이 두 콘텐츠를 가져와야하기 때문에 부모요소로 바구니에 담아서 부모요소에 text를 사용해서 2개의 콘텐츠를 한번에 가져올 수 있다.
