
LBPH 분류기 학습을 배우다. (광주, 인공지능, 과학기술정보통신부, 광주광역시)
1. LBPH 분류기 학습
LBPH 분류기를 학습시키기 전에 이 분류기의 학습과정을 알아보자.
LBPH 분류기는 이미지를 작은 정사각형(셀)으로 나누고 각 정사각형에 특정 조건을 적용해서 이진값을 생성한다. 최종 목표는 작은 정사각형마다 하나의 히스토그램을 그리는 것이다. 히스토그램을 그리는 이유는 히스토그램을 이용해서 얼굴을 비교할 때 사용하기 때문이다. 따라서 각 얼굴마다 히스토그램 SET를 가지고 있다. 새로운 이미지를 분류기에 넣으면 새로운 히스토그램 SET가 생성되는데, 생성된 히스토그램을 학습 시 저장된 모든 히스토그램과 비교한다. 알고리즘의 학습 과정은 각 클래스에 관한 히스토그램을 생성하고 파일로 저장한다. 파일은 저장된 히스토그램과 분류하고자하는 새 이미지의 히스토그램을 비교할 때 사용한다.
1 - 1. 분류기 학습
# x그리드, y그리드 default 8 (8행 8열로 이루어져있다)
lbph_classifier = cv2.face.LBPHFaceRecognizer_create()
lbph_classifier.train(faces, ids)
lbph_classifier.write('lbph_classifier.yml') # 분류기를 저장할 때 기본 형식인 yml
# 파일에는 이미지마다 64 히스토그램이 저장되어 있다. => 8행 8열 이니까위 코드는 분류기를 생성하고 학습시키는 코드이다. 각 얼굴의 픽셀정보와 클래스로 학습한다. 그리고 학습된 분류기를 파일로 저장한다. lbph_classifier.yml 파일에는 이제 학습된 분류기 정보가 담겨있다.
lbph_face_classifier = cv2.face.LBPHFaceRecognizer_create()
lbph_face_classifier.read("/content/lbph_classifier.yml")새로운 변수에 새로운 분류기를 생성하고 미리 학습시켜둔 분류기 파일을 새로운 분류기가 읽도록하여 새로운 분류기가 학습되게끔 한다.
1 - 2. 테스트 이미지 예측
paths = [os.path.join('/content/yalefaces/test', f) for f in os.listdir("/content/yalefaces/test")]
predictions = []
expected_outputs = []
for path in paths:
# 각 테스트 이미지의 경로 path
image = Image.open(path).convert("L")
image_np = np.array(image, 'uint8')
prediction, _ = lbph_face_classifier.predict(image_np)
expected_output = int(os.path.split(path)[1].split('.')[0].replace('subject', ''))
predictions.append(prediction)
expected_outputs.append(expected_output)예측을 해보기 위해 테스트 이미지의 경로들을 paths 리스트에 담는다. for문으로 각 테스트 경로의 이미지를 흑백화하고 넘파이 배열로 바꾸고 픽셀값을 정수화한다. predict 결과값으로 클래스와, 신뢰도가 나오는데 지금 우리는 클래스만 필요하기 때문에 prediction, _로 값을 받아준다. 그리고 각 이미지의 prediction들을 담을 리스트와 기댓값을 담을 리스트를 만들고 결과값과 기댓값을 비교하는 과정이 필요할 것이다.

from sklearn.metrics import accuracy_score
accuracy_score(expected_outputs, predictions)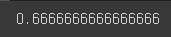
sklearn의 accuracy_score를 사용해서 결과값이 기댓값에 얼마나 정확하게 나왔는지 확인해 볼수 있다. 결과를 보면 0.6666이 나왔는데 그렇게 좋은 결과는 아니다. 따라서 우리는 분류기의 매개변수 값을 조절해서 결과값을 개선해서 예측 신뢰도를 증가시켜야 한다.
2. 매개변수
- Radius : 조건을 적용할 때 사용되는 픽셀 수
- Neighbors : 계산에 필요한 이웃의 수
- grid_x, grid_y : 가로축, 세로축 셀의 개수
- Threshold : 임계값, 감지의 신뢰도 (값이 높을수록 얼굴 인식 품질이 높아진다.)
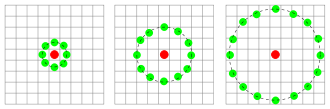
grid_x, gird_y의 default는 8이다. 픽셀의 수가 많아지면 히스토그램 수도 많아지는게 되고 이미지에서 더 많은 패턴을 추출할 수 있어서 좋다. 하지만 계산 시간이 오래걸린다.
다음글에서 매개변수를 적절하게 조절하여 결과값을 개선해보겠다.
인공지능사관학교
나도 이제 AI 전문가! 인공지능사관학교
gj-aischool.or.kr
'딥러닝 > Computer vision' 카테고리의 다른 글
| [Computer Vision] Dlib을 이용한 Face points 얼굴 포인트 감지 및 얼굴 기술자/ 인공지능사관학교 4기 (2) | 2023.11.09 |
|---|---|
| [Computer Vision] Face Recognition (얼굴 인식) 개념 및 이미지 전처리 / 인공지능사관학교 4기 (0) | 2023.10.23 |
| [Computer Vision] Detecting faces with HOG / 인공지능사관학교 4기 (0) | 2023.10.16 |
| [Computer Vision] Face Detection (얼굴 감지) / 인공지능사관학교 4기 (1) | 2023.10.10 |