
인간의 신경망을 모방하여 학습하는 기술인 딥러닝을 배우다.
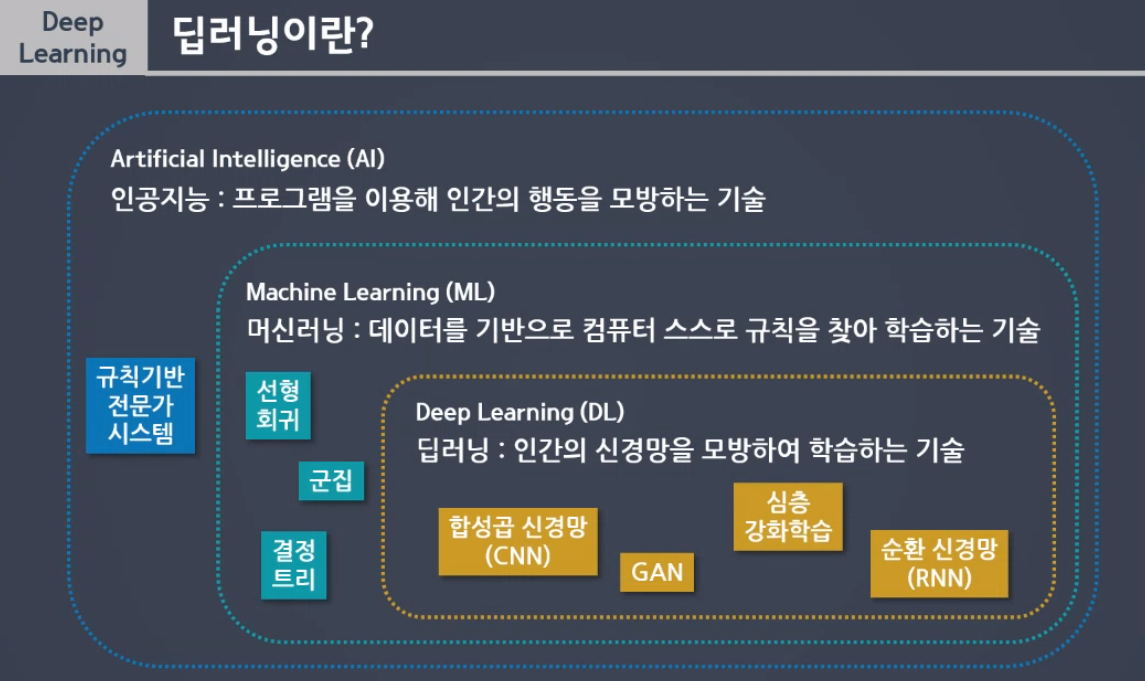
1. 딥러닝 정의
기존에 배운 머신러닝은 모델을 학습하기위해 입력데이터를 사람이 개입해서 모델이 잘 학습할 수 있도록 데이터 전처리 과정을 거친다. 그렇기 때문에 데이터 전처리 과정이 굉장히 중요하다. 좋은 데이터로 모델을 학습해야 좋은 모델과 좋은 결과를 출력하기 때문이다.
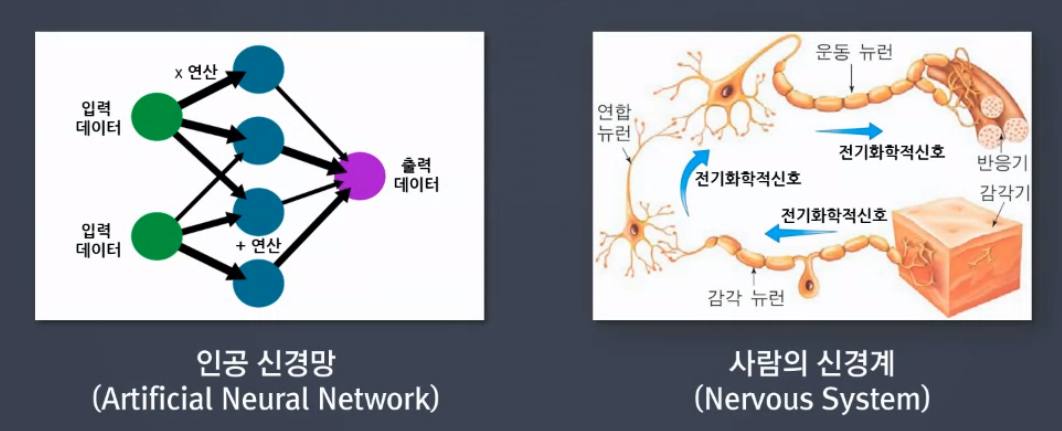
딥러닝은 다르다. 딥러닝은 머신러닝에 속한 개념인데 딥러닝 모델을 학습시킬 때는 입력 데이터에 사람의 개입이 크지 않다. 입력 데이터가 많을수록 모델이 올바른 방향으로 학습한다. 딥러닝 모델은 인간의 신경망을 모방하여 학습한다. 머신러닝에서 배운 선형함수가 딥러닝 모델의 근간이된다. 인간의 신경망인 뉴런이 선형함수라고 생각하면 된다. 여러개의 선형모델들이 병렬적 다층 구조로 이루어져서 종합적으로 판단하고 학습된 후 예측값을 예측한다. 선형함수의 목적은 w, b를 구하는 것이 목적인데 딥러닝도 마찬가지다. 단지 여러개의 선형함수를 사용하기 때문에 구해야 하는 w, b도 여러개이다.
기존 머신러닝의 앙상블 모델과 비슷하게 여러 모델이 최종결과를 출력하지만 딥러닝과 머신러닝의 앙상블 모델의 다른 점이 있다. 앙상블 모델은 각 모델의 결과를 토대로 최종결과를 투표하지만, 딥러닝 모델은 여러 신경망 모델이 한 몸처럼 하나의 결과를 출력한다.

퍼셉트론은 선형 함수와 활성화 함수로 이루어져 있는데 선형함수에서 예측값을 구하고 실제값과의 차이로 (loss function)오차를 구한 후, 활성화 함수를 거쳐서 다음 퍼셉트론이 데이터를 입력 받을 수 있도록 한다. 기존 머신러닝은 사람이 직접 모델에 입력될 데이터를 전처리하는 과정을 거치고 예측값과 실제값의 오차를 확인했어야 했는데, 딥러닝은 입력 데이터에 사람의 개입이 적은 편이다. 신경 써야할 것은 입력될 데이터의 크기, 개수와 같은 정해진 규칙에 맞춰야하는 것이다.
2. 딥러닝 적용 분야

딥러닝은 앞에서 말했다시피 방대한 데이터를 처리할 때 적합한 모델이다. 텍스트, 이미지, 음성, 영상 데이터들은 기존 머신러닝에서 사용된 데이터들과는 다르게 용량이 큰 데이터들이다. 딥러닝 모델로 대량의 데이터에서 복잡하고 계층적인 패턴을 찾아내는 능력이 뛰어난다.
- 인공지능 챗봇 (자연어 처리)
- 가상인물 목소리 생성 (생성 모델)
- 얼굴 / 객체 인식 (이미지 인식)
딥러닝은 인공 신경망이기 때문에 사람이 직접 입력 데이터를 구별해서 좋은 데이터를 만들어줄 필요가 거의 없다.
따라서 데이터 양이 많으면 신경망이 어떤 데이터가 좋은지 안좋은지 구별해낼 수 있다.
'딥러닝 > 딥러닝 기초' 카테고리의 다른 글
| [딥러닝] 퍼셉트론, 다층퍼셉트론 (활성화 함수) (3) | 2023.10.03 |
|---|